1. Introducción
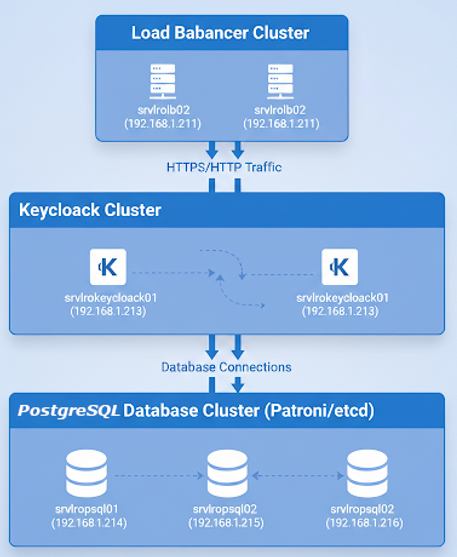
Este manual está diseñado para guiarte a través del proceso de instalación y configuración de una base de datos PostgreSQL en alta disponibilidad utilizando Patroni y etcd como servicio de coordinación. Patroni facilita la gestión del clúster de bases de datos PostgreSQL y asegura la conmutación por error automática, mientras que etcd proporciona la sincronización de la configuración entre los nodos del clúster.
Este tipo de configuración es ideal para entornos de producción donde se necesita garantizar alta disponibilidad y resistencia ante fallos de nodo.
2. Requisitos Previos
Antes de comenzar con la instalación, asegúrate de cumplir con los siguientes requisitos previos:
- Sistema Operativo: GNU/Linux (En este caso emplearemos Debian).
- Privilegios de root: Acceso a una cuenta con permisos de superusuario para realizar instalaciones y configuraciones del sistema.
- Red: Tres servidores (o más) en la misma red con direcciones IP estáticas.
- Conectividad SSH: Asegúrate de que todos los nodos puedan comunicarse entre sí mediante SSH.
- Dependencias: Necesitarás herramientas como
curl, wget, y otros paquetes necesarios para descargar e instalar componentes.
2.1 Elección de la Cantidad de Nodos en Alta Disponibilidad
Cuando se configura un clúster de PostgreSQL en alta disponibilidad con Patroni y etcd, una de las decisiones clave es el número de nodos que formarán parte del clúster. La cantidad de nodos tiene un impacto directo en la tolerancia a fallos, la capacidad de realizar conmutaciones por error y la disponibilidad general del sistema. A continuación, explicamos cómo calcular el número adecuado de nodos y por qué se recomienda utilizar un número impar de nodos en algunos casos.
¿Cuántos Nodos Necesito?
El número mínimo recomendado para configurar un clúster de alta disponibilidad es de tres nodos. Este número de nodos asegura que el sistema sea lo suficientemente robusto como para tolerar fallos de al menos un nodo sin que se pierda la disponibilidad o el consenso en el clúster.
Para calcular el número de nodos necesarios en un clúster con etcd, se sigue una fórmula relacionada con el quorum. El quorum es la cantidad mínima de nodos que deben estar disponibles para que el sistema tome decisiones de manera confiable. Esta fórmula es la siguiente:
quorum=nodos2+1quorum = \frac{nodos}{2} + 1quorum=2nodos+1
Por ejemplo:
- Con 3 nodos: el quorum es de 2 nodos, lo que permite que el sistema siga funcionando si uno de los nodos falla.
- Con 5 nodos: el quorum es de 3 nodos, permitiendo que el sistema siga operativo incluso si dos nodos fallan.
- Con 7 nodos: el quorum es de 4 nodos, lo que permite una mayor tolerancia a fallos.
¿Por qué es importante tener un número impar de nodos?
El uso de un número impar de nodos es fundamental cuando se utilizan tecnologías de consenso, como etcd o Raft, que son responsables de mantener la consistencia de los datos en el clúster. Esto se debe a que el consenso depende de un proceso de votación entre los nodos para tomar decisiones. Si hay un número par de nodos, existe el riesgo de que no se pueda alcanzar un consenso en caso de un fallo, ya que no se podría determinar qué nodo tiene la mayoría.
Por ejemplo:
- Si el clúster tiene 2 nodos y uno de ellos falla, el otro nodo quedaría sin quorum, ya que no puede decidir por sí mismo si el nodo caído debe ser promovido o no.
- Con 3 nodos, si uno falla, los otros dos pueden seguir trabajando y decidir qué hacer con el nodo caído.
Por lo tanto, siempre que se utilicen servicios de coordinación y consenso (como etcd o Consul), es recomendable tener un número impar de nodos en el clúster para garantizar que siempre se pueda alcanzar el quorum y evitar problemas de «split-brain» (división del clúster).
¿Cuándo se podrían usar nodos pares?
En algunos casos, los nodos pares pueden ser adecuados, pero solo para ciertos tipos de servicios que no dependen de un proceso de consenso, como en la distribución de carga o en clústeres de Kubernetes donde los nodos de worker no participan en decisiones críticas de consenso. Algunos ejemplos de estos casos son:
- Balanceadores de carga: En servicios como HAProxy o NGINX, los nodos de balanceo pueden ser pares, ya que su objetivo es distribuir el tráfico sin necesidad de consenso.
- Servidores de aplicaciones: Si el servicio solo necesita alta disponibilidad pero no se requiere un proceso de consenso entre los nodos, los nodos de aplicaciones pueden ser pares.
Resumen
- Para clústeres de alta disponibilidad que utilizan Patroni y etcd, 3 nodos es el mínimo recomendado, y se debe utilizar un número impar para garantizar el consenso y la disponibilidad en caso de fallos.
- 5 nodos es ideal para entornos más grandes o donde se espera una mayor carga, ya que proporciona más tolerancia a fallos.
- El número de nodos puede ser par en servicios que no requieren consenso, como balanceadores de carga o servidores de aplicaciones.
Leer más